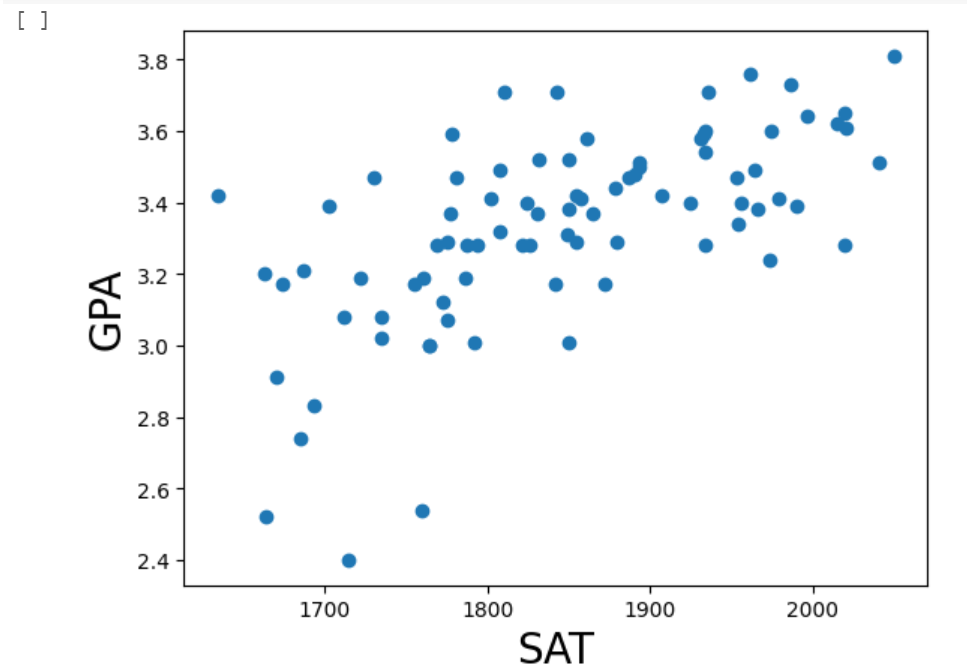
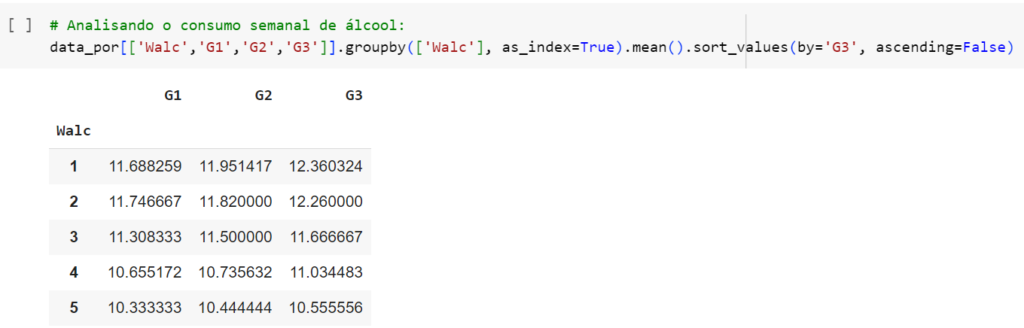
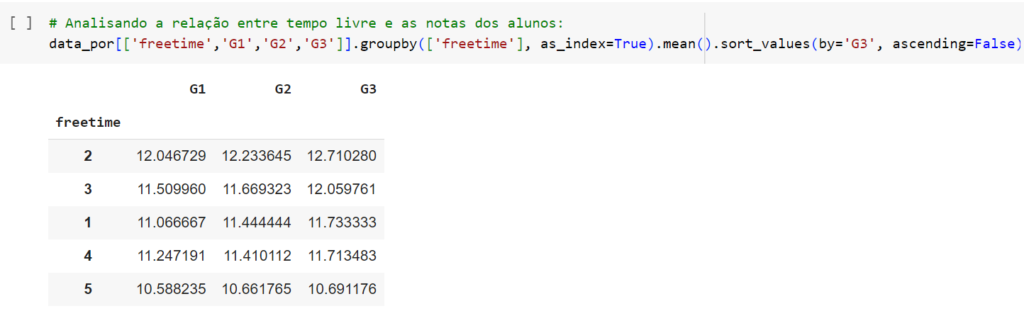
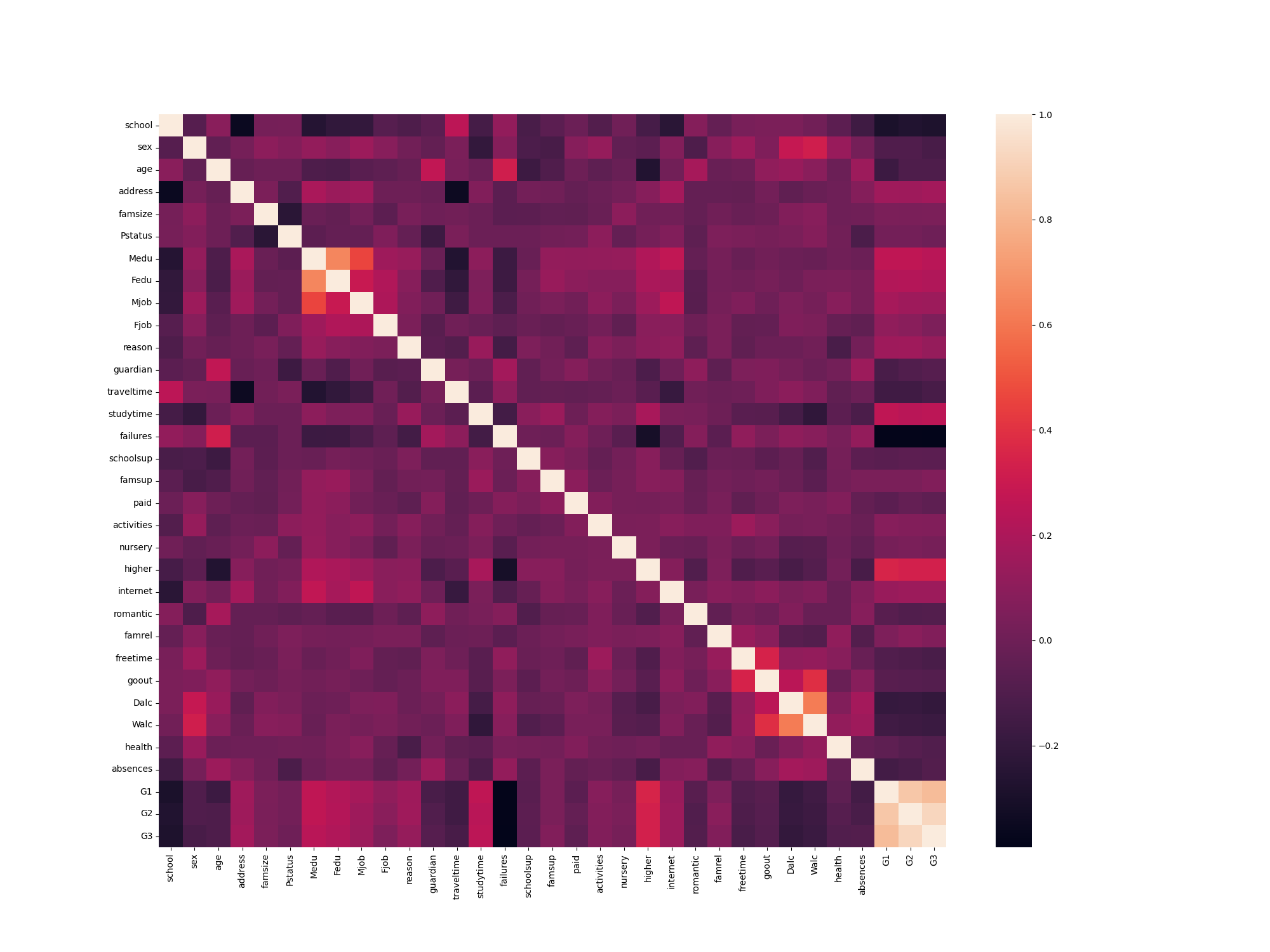
Apesar de, a olho-nu e “logicamente”, a relação entre as variáveis ser clara, introduziremos um conceito final nesse exemplo, que é essencial à Inferência Estatística: o Teste de Hipóteses.
Às vezes, é possível que estatísticas “aparentemente” relacionadas não estejam relacionadas o suficiente para comprovarem o que queremos. Ou, podemos ter viéses, e querermos que dois atributos estejam relacionados. Nesses casos, usamos o teste de hipóteses.
Um teste de hipóteses é uma ferramenta estatística usada para tomar decisões sobre as populações com base nas amostras. Ele está diretamente associado ao intervalo de confiança.
Um intervalo de confiança é uma faixa de valores na qual acredita-se que um parâmetro (como um coeficiente de regressão) esteja com uma certa probabilidade.
Por exemplo, um intervalo de confiança de 95% indica que, se repetíssemos a amostragem muitas vezes, o verdadeiro valor do coeficiente estaria dentro desse intervalo em 95% das vezes.
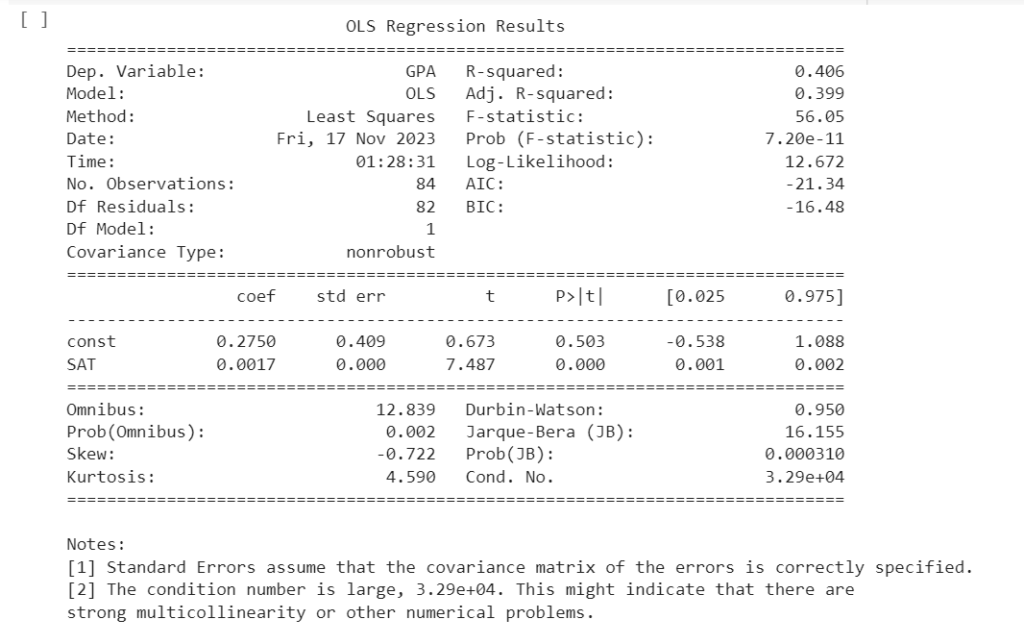
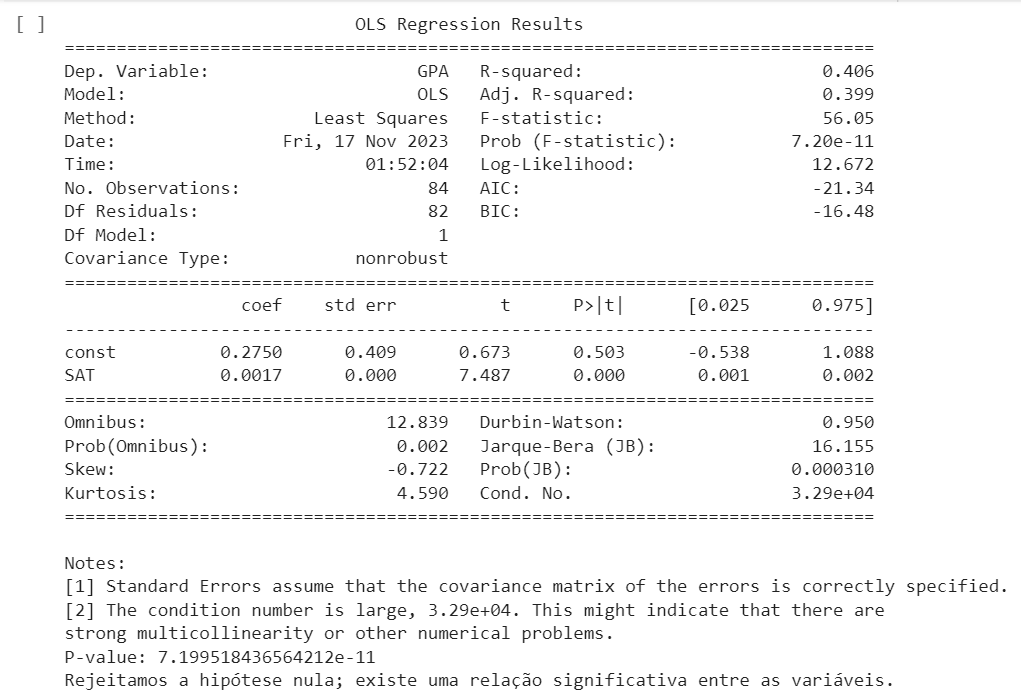
No contexto de regressão, um teste de hipóteses permite avaliar se os coeficientes estimados são estatisticamente significativos. Geralmente, essa avaliação é feita com um intervalo de confiança de 95%.
Um p-valor associado ao teste indica a probabilidade de observar os resultados observados (ou mais extremos) se a hipótese nula de que o coeficiente é zero for verdadeira.
A avaliação da significância estatística ajuda na tomada de decisões sobre quais variáveis incluir ou excluir do modelo. Variáveis estatisticamente insignificantes podem ser removidas, simplificando o modelo sem comprometer sua capacidade explicativa.
Ao realizar o teste de hipóteses, obtemos um p-valor associado ao coeficiente do tamanho da casa. Se o p-valor (100% – intervalo de confiança) for suficientemente baixo, podemos rejeitar a hipótese nula.
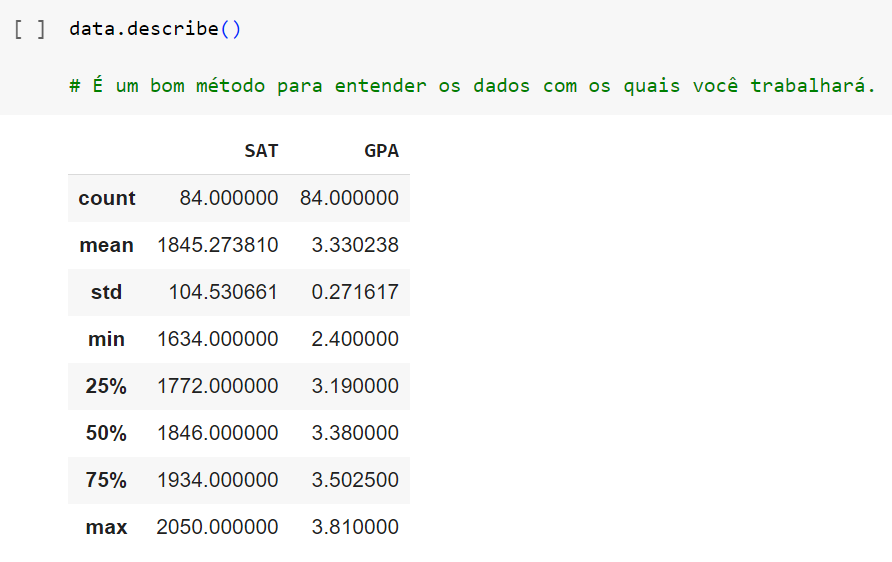
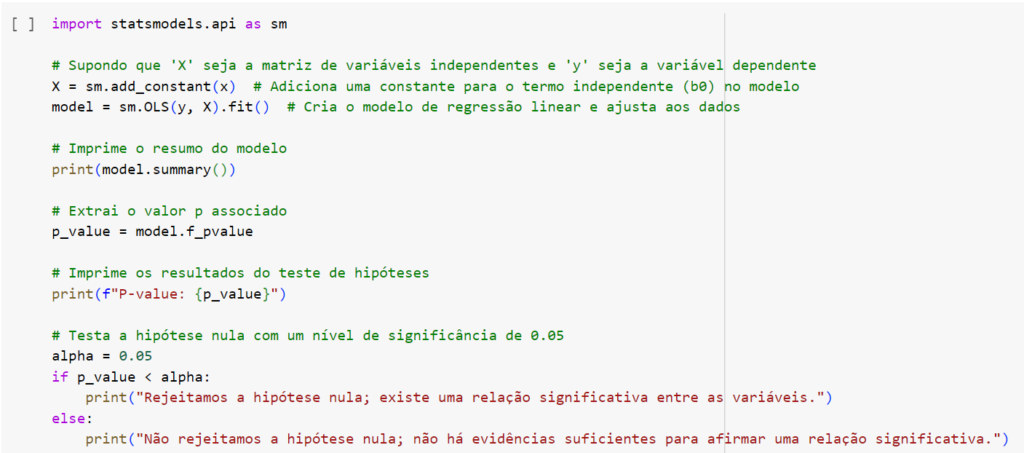
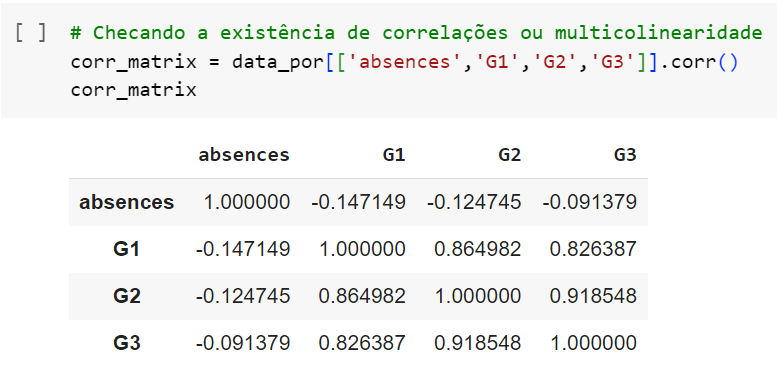
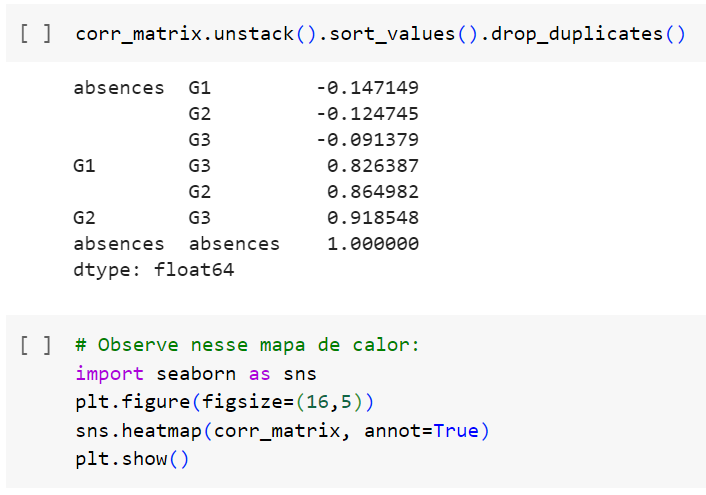
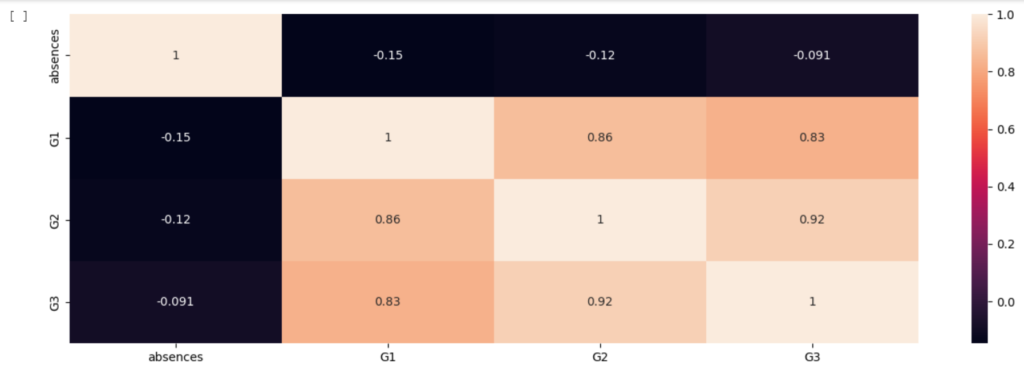
Observemos no código abaixo um exemplo: