
Development of control rules for short-term adjustments in oil reservoir management
Sérgio Ferreira Batista Filho (Master’s student)

Oil reservoir development and management aim at maximizing production and/or profit concerning operational, technological, economic, regulatory, and other constraints. Reservoir development is intrinsically associated with the implementation of the production infrastructure, whereas management regards the operation of this infrastructure. To better structure and to facilitate the study of reservoirs, the infrastructure is mapped in a set of variables for the studied problem, classified according to the reservoir life cycle as variables of project; control and revitalization. One way to support management activities is to rely on historical data of production to make future decisions. In this project, we will use the case study UNISIM-I-M, based on Namorado da Bacia de Campos / RJ field, with data equivalent to real reservoir data. The project objectives are: (1) to establish control rules to be applied over short-term variables and (2) to investigate for how long the reservoir behavior prediction is reliable, based only on historical data. To satisfy the objectives, machine learning and data mining methods will be used. As a result, we expect the development of short-term control rules to maximize production and/or profit over the medium and long term.
Random walk on stock network for portfolio allocation
Washington Burkart (Master’s student)
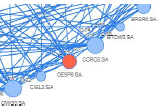
Tactical asset allocation is an important tool for making prots in a portfolio for a given period. Two techniques commonly used by analysts to create a tactical asset portfolio are: technical analysis, for the short term, and fundamentalist analysis, for the long term. Both approaches, however, are subjective, as they depend on the analyst’s knowledge and interpretations. Another aspect that can directly inuence the quality of a portfolio is the number of assets considered for analysis. Human analysts tend to focus on a pre-dened group of assets, limiting choices and, consequently, the possibility of better results. This work proposes an algorithm for automatic recommendation of a stock portfolio, aiming to maximize prot and minimize risk. The proposed method considers the possibly large set of assets as a complex network, in which the nodes represent assets and the edges between them are established according to the correlation between their returns. The choice of assets is made through a random walk on the network, selecting, at the end, the most visited assets. The algorithm includes mechanisms that guarantee the visit to us with positive and negative correlation, which reduces the risk of the portfolio.
A hidden Markov model based device for cattle health monitoring
Luiz Ricardo da Silveira (Master’s student)
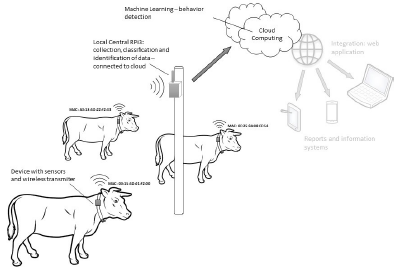
Every year billion dollars are lost due to late diagnosis of diseases that aect cattle herds as a result of the monitoring of health condition only by observation. Thus, this work proposes development of a new Precision Livestock Farming system to monitor cattle’s health condition, which consisting of the development of a new electronic device that will be placed on a neck collar on the animal, with 9-axes motion sensors and a body temperature sensor; a local central Raspberry Pi that will read and compile separately the data sent by each devices; and a machine learning layer. The machine learning layer will use a Hidden Markov Model to map the standard behavior of each animal. This standard behavior is based on monitoring the time spent by the animal on each usual activity throughout the day. To detect disease, the machine learning model will monitor individual abnormal changes in habitual behavior or body temperature, comparing with other animals in same location. This study also includes laboratory testing of the device and will include data collected by eld tests with analyzes and results as described in the task schedule.
Machine learning based surrogate models to accelerate the production strategy selection process
Mei Funcia (Master’s student)
Net Present Value (NPV) is a measure used to estimate the profitability of an investment in a given period of time. In the exploration of an oil field, this value is not only important for the determination of the decision to exploit the field, but also helps in the choice of the best production strategy, which should consider the geology of the reservoir and possible arrangements between the wells; since these characteristics directly influence the amount of oil that will be extracted and in the NPV. These evaluations can be performed with the use of simulators, which, however, require a high computational cost to perform the processing of each production strategy. To minimize the response time of the simulators, this work proposes the use of machine learning algorithms as auxiliary models. The work aims to minimize computational costs by predicting NPV to determine the best oil field production strategy using well location data as predictors.